
PyMySQL 是一个纯 Python 实现的 MySQL 客户端库,用于 Python 程序与 MySQL 数据库的交互。通过安装和引入pymysql模块就可以实现对数据库的各种sql操作。
主要特点
- 纯 Python 实现:不需要 MySQL 客户端库或编译步骤
- 兼容性:支持 Python 3.x(Python 2.7 也支持但已不推荐)
- API 兼容性:与 MySQLdb(Python 2 时代的流行 MySQL 驱动)基本兼容
- 轻量级:不依赖其他大型库
- 活跃维护:开源项目,持续更新
基本用法
pip install pymysql #安装pymysql
import pymysql #引入模块
操作数据库的流程:
1:链接数据库,获取链接对象。
获取链接对象:pymysql.connect(host,port,user,password,database)
2:使用链接对象创建游标对象。游标对象是执行sql语句的。
获取游标对象:链接对象.cursor()
3: 使用游标对象执行sql语句
执行sql语句:游标对象.execute(sql语句)
4:执行的增、删、改操作,需要使用链接对象提交。链接对象.commit()
执行的是查询操作,需要使用获取游标对象的fetchall/fetchone获取查询结果。
fetchall(): 获取查询的所有结果,返回值为元组,该方法是临时性的,所有查询结果只会返回一次。
fetchone(): 获取查询的一个结果,如果有查询结果返回值为元组,如果没有查询结果返回值为None,该方法是临时性的,所有查询结果只会返回一次
5:数据库操作完之后需要关闭游标对象和链接对象。
游标对象.close()
链接对象.close()示例
# 获取链接对象
conn = pymysql.connect(host="192.168.100.195", port=3306, user="root", password="123456", database="test68")
# 创建游标对象
cursor = conn.cursor()
# 执行sql语句
sql_data = """
create table if not exists class(
id int auto_increment primary key,
name varchar(20) not null
)engine=InnoDB default charset=utf8mb4;
"""
#关闭链接
cursor.execute(sql_data) 数据库连接池连接池
对于一个简单的数据库应用,由于对于数据库的访问不是很频繁。这时可以简单地在需要访问数据库时,就新创建一个连接,用完后就关闭或销毁它,这样做也不会带来什么明显的性能上的开销。但是对于一个复杂的数据库应用,情况就完全不同了。频繁的建立、关闭连接,会极大的减低系统的性能,因为对于连接的使用成了系统性能的瓶颈
原理
连接池是一种管理数据库连接的技术,它预先创建并维护一定数量的数据库连接,当应用程序需要时从池中获取连接,使用完毕后归还到池中而不是直接关闭,这样可以显著提高数据库操作性能。
连接池好处
- 减少连接创建开销:建立数据库连接是昂贵的操作
- 控制连接数量:防止过多连接耗尽数据库资源
- 提高响应速度:复用已有连接,避免频繁创建和关闭
- 统一管理连接:提供更健壮的连接处理机制
Python常用连接池
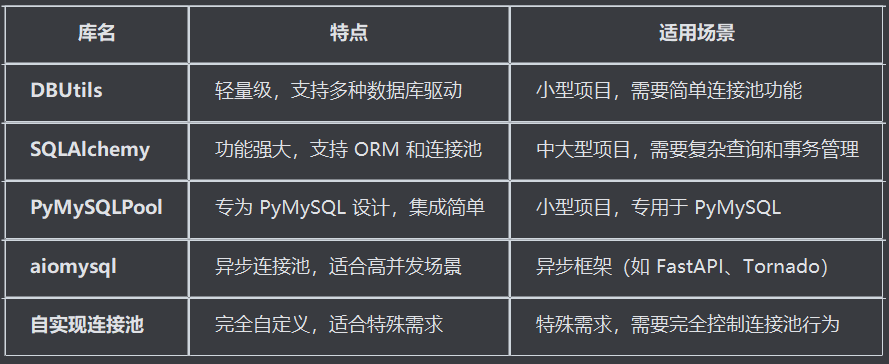
安装并使用连接池
pip install dbutils
import pymysql
from dbutils.pooled_db import PooledDB # 连接池库
# 创建连接池
pool = PooledDB(
creator=pymysql,
host='localhost',
user='root',
password='123456',
database='test',
maxconnections=5, # 最大连接数
mincached=2, # 初始化时最少空闲连接
blocking=True # 连接池满时是否阻塞等待
)
connection = pool.connection() # 创建游标对象进阶操作
手动释放资源:通过命令close()来关闭游标对象和链接对象
使用with...as...自动释放:
with connection.cursor() as cursor:
cursor.execute('create table class (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(20))')事务操作:将多个操作看成一个整体,要么都执行,都么都不执行。只要有一个操作失败,所有操作都回滚到最初的时候。事务有四大特性ACID:
# 演示tom跟jack借5分
try:
with connection.cursor() as cursor:
sql1 = "UPDATE user SET score = score - 5 WHERE name = %s"
sql2 = "UPDATE user SET score = score + 5 WHERE neme = %s" #把neme改成name就会正常执行
cursor.execute(sql1, ('jack',))
cursor.execute(sql2, ('tom',))
connection.commit() # 提交事务
except Exception as e:
connection.rollback() # 回滚事务
print(f"事务失败: {e}")思考
当某些资源(如数据库连接、线程池、缓存、日志系统等)在整个应用中只需要一个实例,重复创建会浪费资源。
单例模式:(Singleton Pattern)是一种常用的设计模式,其主要目的是确保一个类 只有一个实例,并提供一个 全局访问点。它在某些场景下非常有用,但也可能被滥用,因此需要合理使用。
适合单例模式的情况:
- 数据库连接池(如
DataSource) - 日志记录器(如
Logger) - 配置管理器(如
AppConfig) - 缓存系统(如
RedisClient) - 线程池(如
ExecutorService)
示例
class DB:
_instance = None
def __new__(cls, *args, **kwargs):
"""__new__分配类对象的内存空间"""
if cls._instance is None:
# cls._instance = super(cls, cls).__new__(cls, *args, **kwargs)
cls.pool = PooledDB(
creator=pymysql,
host="36.139.193.99",
port=3306,
user="root",
password="Rhrc@2024",
database="eip8",
maxconnections=10,
mincached=5,
charset="utf8mb4"
)
cls._instance = super().__new__(cls, *args, **kwargs)
return cls._instance
def delete(self, sql_statement):
"""执行删除的sql语句"""
if isinstance(sql_statement, str) and sql_statement.lower().startswith("delete"):
# 尝试执行sql语句
conn = self.pool.connection() # 获取链接对象
try:
with conn.cursor() as cursor: # 获取游标对象
cursor.execute(sql_statement)
except Exception as e:
raise ValueError("sql语句中的字段或者表面错误")
else:
conn.commit()
else:
raise ValueError("sql语句错误")问:为什么 cls._instance不能直接调用DB
因为调用 DB() → 触发 DB.__new__,在 __new__ 内部又调用 cls.__new__(即DB.__new__),重复第 2 步,直到程序崩溃。
问:为什么 super().__new__ 不会循环?
因为调用DB() → 触发DB.__new__,super().__new__(cls) 找到父类 object 的 __new__,分配内存。返回创建好的实例,后续调用直接返回 _instance。
问:python2和pyhon3的格式不一致
在 Python 3 中,super() 无需显式传递类和实例参数(super(cls, cls) 或 super(cls, self)),它会根据调用上下文自动确定:在 实例方法 中,super() 自动绑定到当前实例。在 类方法(如 __new__)中,super() 自动绑定到当前类。
Comments NOTHING