
前言
上一次我们理解了Jmeter如何连接数据库,这次有个问题又出现在我眼前,那就是我通过Select语句查询了数据之后虽然可以通过手动复制的形式将数据添加到CSV文件中做数据驱动,但是如果查询的数量过大且都需要使用的话最好的方式就是通过代码来操作。这里我提供了两套方案。
使用JDBC变量+计数器实现
设置通过JDBC请求成功后赋值给变量,若查询多个值可以直接在后面设置下一个变量(我这里是Id)。
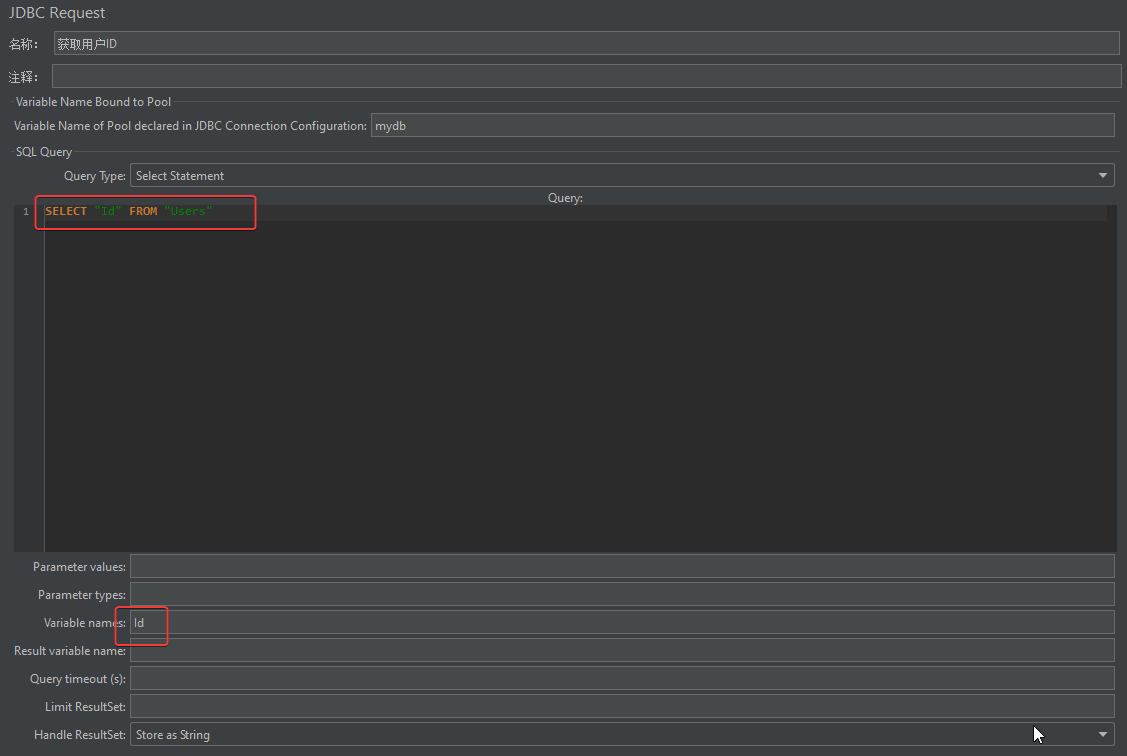
然后通过调试取样器后能看到变量是通过Id_num的形式存在。
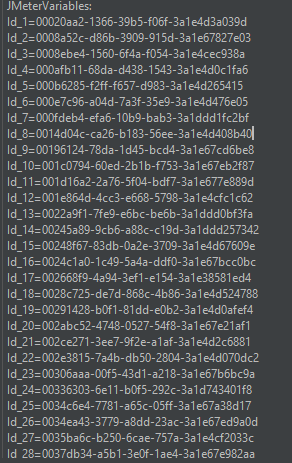
通过计数器能够设置数据有多少行,然后通过变量Id+计数器的形式依次填充参数,但是这种方式不能对每个结果进行不同断言并且只能从1开始,不能取随机。
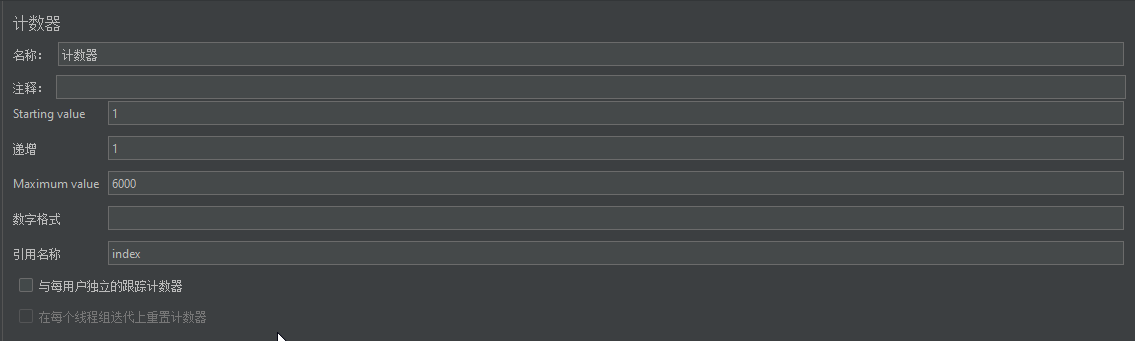
${__V(Id_${index})} #这样就可以直接进行遍历使用使用Beanshell实现
在设置JDBC变量的基础上使用beanshell将数据输出到CSV文件中(这里Beanshell可以是后置处理器或者Jsr223后置处理器)
//创建文件对象
FileWriter fw = new FileWriter("C:/Users/ds/Desktop/Id.csv", true);
//创建一个字符串存储地址
BufferedWriter bufw = new BufferedWriter(fw);
//获取sql查询结果的行数
String num = vars.get("Id_#");
//字符串转换成int
int count = Integer.parseInt(num);
//控制循环次数,写入count行文件
for(int i = 1; i <= count; i++) {
//获取sql查询结果第i行的数据
String str = vars.get("Id_" + i);
//将数据写入磁盘文件中
bufw.write(str);
//执行
bufw.write("\n"); //\n\n是空两行
}
//文件写入结束后,关闭流
bufw.close();
fw.close();保留原本的数据中的字符并且使用UTF-8编码(多个值输出)
import java.io.*;
// 创建UTF-8编码的文件写入器
BufferedWriter out = new BufferedWriter(
new OutputStreamWriter(
new FileOutputStream("C:/Users/ds/Desktop/Id.csv", true),
"UTF-8"
)
);
// 写入UTF-8 BOM头
out.write("\uFEFF");
int count = Integer.parseInt(vars.get("Id_#"));
for(int i = 1; i <= count; i++) {
String id = vars.get("Id_" + i) == null ? "" : vars.get("Id_" + i);
String name = vars.get("Name_" + i) == null ? "" : vars.get("Name_" + i);
// 用双引号包裹所有字段,保留所有原始字符
out.write("\"" + id.replace("\"", "\"\"") + "\",\"" + name.replace("\"", "\"\"") + "\"");
out.newLine();
}
out.close();使用JSR 223实现
import sys
# 创建文件对象 - 使用追加模式
csv_file = "C:/Users/ds/Desktop/Id.csv"
# 获取sql查询结果的行数
num = vars.get("Id_#")
# 字符串转换成int
count = int(num)
# 打开文件,使用追加模式(Jython不支持encoding参数)
with open(csv_file, 'a') as f: # 去掉encoding参数
# 控制循环次数,写入count行文件
for i in range(1, count + 1):
# 获取sql查询结果第i行的数据
str_value = vars.get("Id_" + str(i))
# 将数据写入磁盘文件中
if str_value:
f.write(str_value)
# 写入换行符
f.write("\n")
# 注意:with open会自动关闭文件,不需要手动close()如果是多个值且带UTF-8编码(jython)
from java.io import FileOutputStream, BufferedWriter, OutputStreamWriter
from java.nio.charset import StandardCharsets
fos = FileOutputStream("C:/Users/ds/Desktop/Id.csv", True)
# 添加UTF-8 BOM头
fos.write(b'\xEF\xBB\xBF')
osw = OutputStreamWriter(fos, StandardCharsets.UTF_8)
out = BufferedWriter(osw)
count = int(vars.get("Id_#"))
for i in range(1, count + 1):
# 获取原始数据(不进行任何清洗)
strid = vars.get("Id_" + str(i))
strname = vars.get("Name_" + str(i))
# 处理None值
if strid is None:
strid = ""
if strname is None:
strname = ""
# 保留所有原始字符,只转义双引号,然后包裹
# 这样可以保留:空格、中文逗号、特殊符号、换行符等所有字符
escaped_id = '"' + strid.replace('"', '""') + '"'
escaped_name = '"' + strname.replace('"', '""') + '"'
# 写入数据
out.write(escaped_id + ',' + escaped_name)
out.newLine()
out.close()
osw.close()
fos.close()
Comments NOTHING