
基本介绍
web自动化是通过python+selenium+unitest进行配置文件、数据文件、代码文件、调用文件之间的分层,相较于接口自动化,web自动化会多出两个层级。操作层和Runner层。
以下为web自动化的层级(unittest实现)
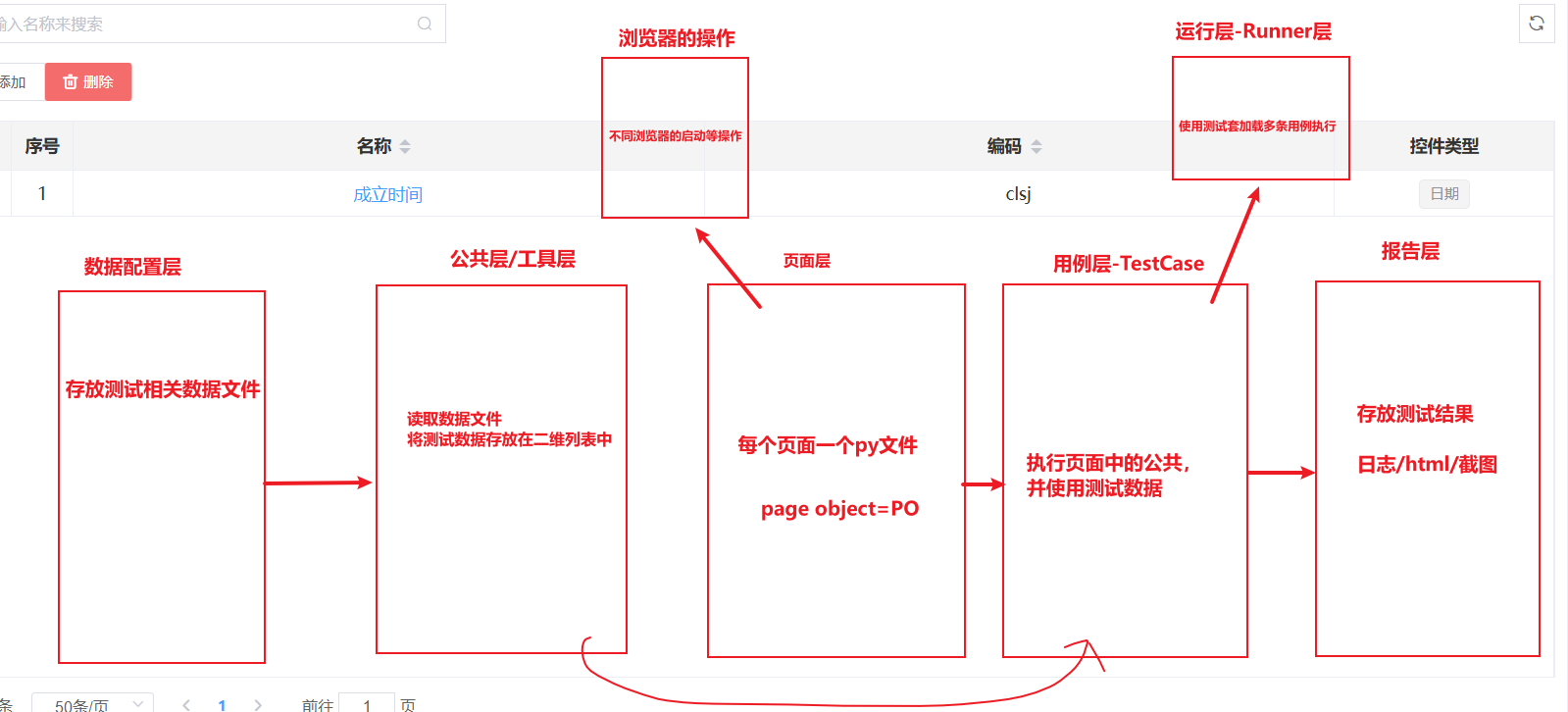
- 数据配置层:分别存储用户的基本配置、用例数据、请求的参数、期望的数据文件、sql语句、driver文件、定位数据文件。
- 工具层/公共层:将数据配置层中各种从配置文件中读取的数据拼接好的完整数据放在一个二维列表中
,封装数据库的连接,封装前置杀死端口进程的方法。 - 页面层:封装每一个页面的具体操作,如点击、输入等操作。
- 浏览器层:创建浏览器对象,封装初始化chrome等浏览器的debug操作,封装各种定位方法、输入、点击方法。
- 用例层:使用 unittest参数化并调用公共层中的二维列表中的数据并配置截图功能。
- 运行层:使用测试套加载并执行多条用例。
- 报告层:存放测试的结果,用于查阅或输出。
实战步骤
首先还是理清每个文件夹所对于的层级和功能,在每个层级中的代码和数据都是相互关联的,首先在根目录的__init__.py文件下编写日志(与接口自动化一致),以下是具体的文件层级。
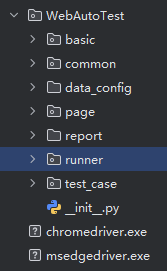
数据配置层
WebAutoTest.xlsx

在此文件中存放测试用例的基本数据,模块名称、功能名称、用例标题、等级、用例数据标题、期望数据标题、sql语句标题。也是将具体的用例数据、期望数据、Sql语句存放在另一个json文件当中。
config.ini
[file]
# 配置文件
excel=WebAutoTest.xlsx
case=case_data.json
expect=expect_data.json
sql=sql_data.json
# 定位值的文件
selector=selector.yaml
[url]
index=http://x.x.x.x:x/mvue/login
[table]
name=Web自动化
[mysql]
host=x.x.x.x
port=3306
user=root
password=xxxxxx
database=eip8
[case]
case_dir=test_case
[report]
report_dir=html
image_dir=image
[driver]
# 浏览器驱动文件路径
chrome=chromedriver.exe
edge=msedgedriver.exe
[chrome]
# chrome浏览器的启动信息
binary_location=C:\Program Files\Google\Chrome\Application\chrome.exe
data_dir=E:\python cun\python 整合\2025-8-04_selenium\code\WebAutoTest\data_config\chromeData
port=6789
[edge]
# edge浏览器启动信息
binary_location=C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe
data_dir=D:\桌面\edgeData
port=6789在此文件中存放基本的配置信息,如浏览器的文件、浏览器驱动文件等。
case_data.json

在此文件中存放需要输入的具体数据,通过模块名称、功能名称、用例标题来确认一个用例数据。
expect_data.json
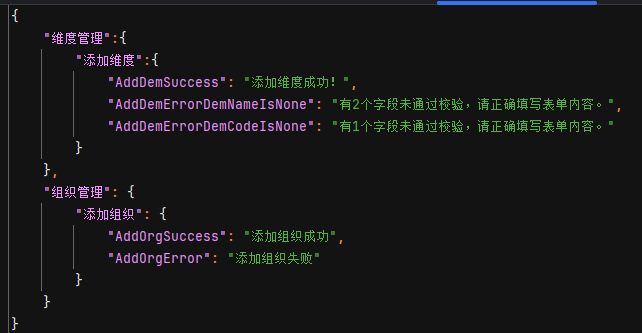
在此文件中存放期望的数据来进行断言,通过模块名称、功能名称、期望标题来确认一个期望数据。
sql_data.json
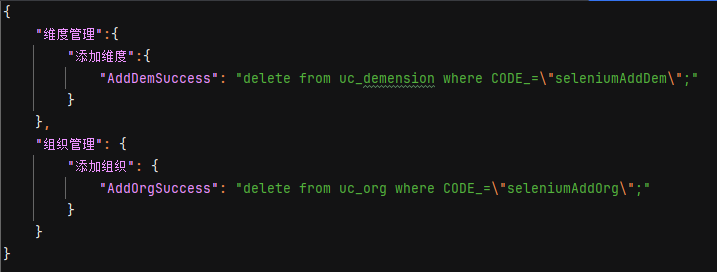
在此文件中存放具体的sql语句,通过模块名称、功能名称、sql标题来确认一个sql语句。
selector.yaml
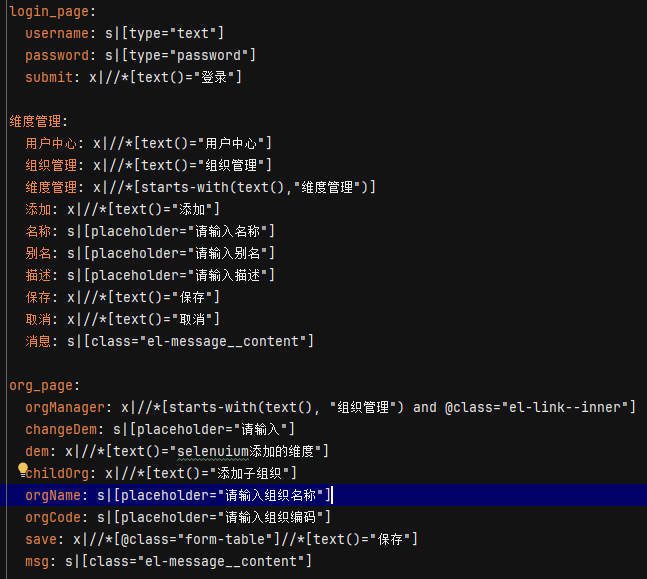
在此文件中存放定位的类型、具体的参数,通过模块名称、页面关键字、定位参数构成。
公共层
read.ini.py
整理思路:首先创建单例模式来进行各种文件的路径读取,然后分别封装方法来读取路径,如读取file节点下的文件路径、url、工作表名称、数据库连接信息、用例执行时所需的路径、报告的路径、驱动文件的路径、本地浏览器的路径。
创建单例进行路径读取
import configparser
import os
from WebAutoTest import log
class ReadIni:
__instance = None
@log
def __new__(cls, *args, **kwargs):
if cls.__instance is None:
cls.project_dir = os.path.dirname(os.path.dirname(__file__))
cls.data_config = os.path.join(cls.project_dir, "data_config")
ini_path = os.path.join(cls.data_config, "config.ini")
cls.conf = configparser.ConfigParser()
cls.conf.read(ini_path, encoding="utf-8")
cls.__instance = super().__new__(cls, *args, **kwargs)
return cls.__instance创建get_file_path方法
@log
def get_file_path(self, key):
"""根据key,获取file节点下文件的路径"""
return os.path.join(self.data_config, self.conf.get("file", key))创建get_url方法
@log
def get_url(self, key):
"""根据key,获取被测系统的访问路径"""
return self.conf.get("url", key)创建get_table_name
@log
def get_table_name(self, key):
"""根据key,获取工作表的名称"""
return self.conf.get("table", key)创建get_mysql_connect_msg
@log
def get_mysql_connect_msg(self, key):
"""根据key, 获取数据库的链接信息"""
return self.conf.get("mysql", key)创建get_case_dir
@log
def get_case_dir(self, key):
"""根据key,获取用例执行时所需的路径"""
return os.path.join(self.project_dir, self.conf.get("case", key))创建get_report_dir
@log
def get_report_dir(self, key):
"""根据key,获取用例执行后所需的路径"""
report_dir = os.path.join(self.project_dir, "report")
return os.path.join(report_dir, self.conf.get("report", key))创建get_driver_path
@log
def get_driver_path(self, key):
"""根据key,获取驱动文件的路径"""
return os.path.join(self.data_config, self.conf.get("driver", key))创建get_chrome_msg
@log
def get_chrome_msg(self, key):
"""根据key,获取chrome浏览器启动时的数据"""
return self.conf.get("chrome", key)创建get_edge_msg
@log
def get_edge_msg(self, key):
"""根据key,获取edge浏览器启动时的数据"""
return self.conf.get("edge", key)db.py
整理思路:首先创建单例模式封装数据库的连接池,再封装查询和删除的方法。
import pymysql
from dbutils.pooled_db import PooledDB
from WebAutoTest import log
from WebAutoTest.common.read_ini import ReadIni
class DB:
__instance = None
ini = ReadIni()
@log
def __new__(cls, *args, **kwargs):
"""创建连接池"""
if cls.__instance is None:
cls.pool = PooledDB(
creator=pymysql,
host=cls.ini.get_mysql_connect_msg("host"),
port=int(cls.ini.get_mysql_connect_msg("port")),
user=cls.ini.get_mysql_connect_msg("user"),
password=cls.ini.get_mysql_connect_msg("password"),
database=cls.ini.get_mysql_connect_msg("database"),
maxconnections=10,
mincached=5,
blocking=True
)
cls.__instance = super().__new__(cls, *args, **kwargs)
return cls.__instance
@log
def __init__(self):
"""获取链接对象"""
self.conn = self.pool.connection()
@log
def delete(self, sql_sentence):
"""执行删除的sql语句"""
if isinstance(sql_sentence, str) and sql_sentence.lower().startswith("delete"):
with self.conn.cursor() as cursor:
cursor.execute(sql_sentence)
self.conn.commit()
else:
raise ValueError("删除的sql语句错误")
@log
def select(self, sql_sentence):
"""执行查询的sql语句"""
if isinstance(sql_sentence, str) and sql_sentence.lower().startswith("select"):
with self.conn.cursor() as cursor:
cursor.execute(sql_sentence)
select_result = cursor.fetchone()
if select_result:
return select_result[0]
else:
raise ValueError("删除的sql语句错误")
@log
def close(self):
"""关闭链接对象"""
self.conn.close()read_json.py
整理思路:创建此文件来读取json的路径,将json文件的数据序列化为python对象返回
import json
import os
from WebAutoTest import log
@log
def read_json(path):
if isinstance(path, str) and os.path.isfile(path) and path.endswith(".json"):
with open(path, mode="r", encoding="utf-8") as f:
return json.load(f)
else:
raise FileNotFoundError("文件路径错误")read_yaml.py
整理思路:创建此文件来读取yaml文件,将yaml文件的数据序列化为python对象返回
import os
import yaml
from WebAutoTest import log
from WebAutoTest.common.read_ini import ReadIni
@log
def read_yaml(file_path):
"""读取yaml文件,将yaml文件的数据序列化为python对象返回"""
if isinstance(file_path, str) and os.path.isfile(file_path) and file_path.endswith(".yaml"):
with open(file_path, mode='r', encoding="utf-8") as f:
return yaml.load(f, Loader=yaml.FullLoader)
else:
raise FileNotFoundError("文件路径错误")utils.py
整理思路:封装需要启动debug模式的前置操作,杀死相应的端口号。
import os
def kill_process(port):
"""执行命令,结束进程"""
res = os.popen(f'netstat -ano | findstr "{port}"')
lines = res.readlines()
for line in lines:
if "0.0.0.0:0" in line:
pid = line.split(" ")[-1].strip()
os.popen(f'taskkill /pid {pid}')
breakread_excel.py
整理思路:首先通过之前的方法读取文件的路径和excel文件的信息,封装excel的读取以及格式转换,封装每行的读取方法,最后将读取的内容整理放入到二维列表中。
创建class ReadExcel
整理思路:初始化excel文件的路径和信息
import openpyxl
from WebAutoTest import log
from WebAutoTest.common.read_ini import ReadIni
from WebAutoTest.common.read_json import read_json
class ReadExcel:
@log
def __init__(self, module, func):
"""根据模块和功能名称获取指定的用例"""
ini = ReadIni()
self.module = module
self.func = func
# 获取文件的路径
case_data_path = ini.get_file_path("case")
expect_data_path = ini.get_file_path("expect")
sql_data_path = ini.get_file_path("sql")
self.case_data_dict = read_json(case_data_path)
self.expect_data_dict = read_json(expect_data_path)
self.sql_data_dict = read_json(sql_data_path)
# 获取excel文件的信息
excel_path = ini.get_file_path("excel")
table_name = ini.get_table_name("name")
wb = openpyxl.load_workbook(excel_path)
self.ws = wb[table_name]创建方法读取excel各行内容
@log
def __cell_value(self, column, row):
value = self.ws[column + str(row)].value
if isinstance(value, str) and len(value.strip()) > 0:
return value.strip()
@log
def module_name(self, row):
return self.__cell_value("b", row)
@log
def func_name(self, row):
return self.__cell_value("c", row)
@log
def case_data(self, row):
case_data_key = self.__cell_value("f", row)
module_name = self.module_name(row)
func_name = self.func_name(row)
if module_name and func_name and case_data_key:
if module_name == self.module and func_name == self.func:
return self.case_data_dict[module_name][func_name][case_data_key]
@log
def expect_data(self, row):
expect_data_key = self.__cell_value("g", row)
module_name = self.module_name(row)
func_name = self.func_name(row)
if module_name and func_name and expect_data_key:
if module_name == self.module and func_name == self.func:
return self.expect_data_dict[module_name][func_name][expect_data_key]
@log
def sql_data(self, row):
sql_data_key = self.__cell_value("h", row)
module_name = self.module_name(row)
func_name = self.func_name(row)
if module_name and func_name and sql_data_key:
if module_name == self.module and func_name == self.func:
return self.sql_data_dict[module_name][func_name][sql_data_key]创建get_data
@log
def get_data(self):
list_data = []
for row in range(2, self.ws.max_row+1):
case = self.case_data(row)
expect = self.expect_data(row)
sql = self.sql_data(row)
if expect:
list_data.append([case, expect, sql])
else:
return list_data页面层
整理思路:这一层主要存放用户执行浏览器的对象步骤,如登录网页的步骤,输入用户名密码然后确认。根据页面的不同,此代码也不同。
login_page.py
import time
from WebAutoTest import log
from WebAutoTest.basic.basic import Basic
class LoginPage(Basic):
def __init__(self, browser="c"):
super().__init__(browser)
@log
def login_func(self, username, password):
"""登录功能"""
self.send_keys(self.data['login_page']['username'], username)
self.send_keys(self.data['login_page']['password'], password)
self.click(self.data['login_page']['submit'])
time.sleep(0.8)
# 截图
# self.get_png(f"用户名={username}_密码={password}.png")
return self.driver.page_sourcedem.page.py
import time
from selenium.webdriver import Keys
from WebAutoTest.page.login_page import LoginPage
class DemPage(LoginPage):
def __init__(self, browser="c"):
super().__init__(browser)
self.login_func("admin", "123456")
self.click(self.data["维度管理"]["用户中心"])
self.click(self.data["维度管理"]["组织管理"])
self.click(self.data["维度管理"]["维度管理"])
def add_dem(self, name, code, msg):
self.click(self.data["维度管理"]["添加"])
self.send_keys(self.data["维度管理"]["名称"], name)
time.sleep(0.5)
self.send_keys(self.data["维度管理"]["别名"], Keys.LEFT_CONTROL + "a")
self.send_keys(self.data["维度管理"]["别名"], Keys.LEFT_CONTROL + "x")
self.send_keys(self.data["维度管理"]["别名"], code)
self.send_keys(self.data["维度管理"]["描述"], msg)
self.click(self.data["维度管理"]["保存"])
time.sleep(1)
content = self.text(self.data["维度管理"]["消息"])
if "成功" not in content:
self.click(self.data["维度管理"]["取消"])
return content浏览器层
整理思路:封装需要启动的浏览器,如chrome、edge、firefox等。封装各种定位方式,如css,xpath等。封装显示等待的方法,解决页面加载和元素渲染往往不是同步。
basic.py
import os
import time
import random
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from WebAutoTest import log
from WebAutoTest.common.read_ini import ReadIni
from WebAutoTest.common.read_yaml import read_yaml
from WebAutoTest.common.utils import kill_process
class Basic:
ini = ReadIni() # 创建为类属性,后面直接使用。
data = read_yaml(ini.get_file_path("selector")) # 获取定位的数据
@log
def __init__(self, browser: str="c"):
"""根据不同的名称,启动不同的浏览器"""
browser = browser.lower()
if browser == "c" or browser == "chrome":
"""执行名称启动chrome浏览器"""
kill_process(self.ini.get_chrome_msg('port'))
time.sleep(0.2)
os.popen(f'''"{self.ini.get_chrome_msg('binary_location')}" --remote-debugging-port={self.ini.get_chrome_msg('port')} --user-data-dir="{self.ini.get_chrome_msg('data_dir')}"''')
time.sleep(0.8)
options = webdriver.ChromeOptions()
options.binary_location = self.ini.get_chrome_msg('binary_location')
options.add_experimental_option("debuggerAddress", f"127.0.0.1:{self.ini.get_chrome_msg('port')}")
self.driver = webdriver.Chrome(service=webdriver.ChromeService(self.ini.get_driver_path("chrome")), options=options)
elif browser == "e" or browser == "edge":
"""启动edge浏览器"""
kill_process(self.ini.get_edge_msg('port'))
time.sleep(0.2)
os.popen(f'''"{self.ini.get_edge_msg('binary_location')}" --remote-debugging-port={self.ini.get_edge_msg('port')} --user-data-dir="{self.ini.get_edge_msg('data_dir')}"''')
time.sleep(0.8)
options = webdriver.EdgeOptions()
options.binary_location = self.ini.get_edge_msg('binary_location')
options.add_experimental_option("debuggerAddress", f"127.0.0.1:{self.ini.get_edge_msg('port')}")
self.driver = webdriver.Edge(service=webdriver.EdgeService(self.ini.get_driver_path("edge")), options=options)
else:
raise ValueError("浏览器的名称传入错误")
# 将理论的窗口最大化
self.driver.maximize_window()
# 访问url
self.driver.get(self.ini.get_url("index"))
@log
def selector_located(self, value: str):
"""
x | //*[text()="用户中心"] ==> (By.XPATH, '//*[text()="用户中心"]')
x-->By.XPATH, //*[text()="用户中心"]
i ==> id
n ==> name
t ==> tag_name
c ==> class_name
l ==> link_text
p ==> partial_link_text
x ==> xpath
s ==> css_selector
"""
selector = value.split("|")[0].strip().lower()
located = value.split("|")[1].strip()
# i ==> id
if selector == "i" or selector == "id":
return By.ID, located
# n ==> name
elif selector == "n" or selector == "name":
return By.NAME, located
# t ==> tag_name
elif selector == "t" or selector == "tag":
return By.TAG_NAME, located
# c ==> class_name
elif selector == "c" or selector == "class":
return By.CLASS_NAME, located
# l ==> link_text
elif selector == "l" or selector == "link":
return By.LINK_TEXT, located
# p ==> partial_link_text
elif selector == "p" or selector == "partial":
return By.PARTIAL_LINK_TEXT, located
# x ==> xpath
elif selector == "x" or selector == "xpath":
return By.XPATH, located
# s ==> css_selector
elif selector == "s" or selector == "css":
return By.CSS_SELECTOR, located
else:
raise ValueError("定位方式错误")
@log
def presence(self, value):
"""expected_conditions.presence_of_element_located函数的封装"""
return WebDriverWait(self.driver, 5).until(EC.presence_of_element_located(self.selector_located(value)))
@log
def presences(self, value):
"""expected_conditions.presence_of_all_elements_located函数的封装"""
return WebDriverWait(self.driver, 5).until(EC.presence_of_all_elements_located(self.selector_located(value)))
@log
def visibility(self, value):
"""expected_conditions.visibility_of_element_located函数的封装"""
return WebDriverWait(self.driver, 5).until(EC.visibility_of_element_located(self.selector_located(value)))
@log
def send_keys(self, selector, value):
"""元素出现在页面上,给元素输入一个值"""
self.visibility(selector).send_keys(value)
@log
def click(self, value):
"""expected_conditions.element_to_be_clickable函数的封装"""
WebDriverWait(self.driver, 5).until(EC.element_to_be_clickable(self.selector_located(value))).click()
@log
def get_png(self, file_name):
# 获取存储图片的目录
image_dir = self.ini.get_report_dir("image_dir")
self.driver.get_screenshot_as_file(os.path.join(image_dir, file_name))
@log
def text(self, value):
"""对元素的text操作进行封装"""
return self.presence(value).text
@log
def close(self):
self.driver.close()用例层
整理思路:以参数化的形式对每个页面进行调用二维数据表,再调用截图记录结果。
test_dem.py
import unittest
from parameterized import parameterized
from WebAutoTest.common.db import DB
from WebAutoTest.common.read_excel import ReadExcel
from WebAutoTest.page.dem_page import DemPage
class TestDem(unittest.TestCase):
@classmethod
def setUpClass(cls):
# 获取DemPage类对象
cls.dem = DemPage()
cls.db = DB()
@classmethod
def tearDownClass(cls):
cls.dem.close()
@parameterized.expand(ReadExcel("维度管理", "添加维度").get_data())
def test_add_dem(self, case_data, expect_data, sql_data):
if sql_data:
self.db.delete(sql_data)
res = self.dem.add_dem(name=case_data[0], code=case_data[1], msg=case_data[2])
# 加截图
self.dem.get_png(f"{expect_data}.png")
self.assertEqual(expect_data, res)test_org.py
import unittest
from parameterized import parameterized
from WebAutoTest.common.db import DB
from WebAutoTest.common.read_excel import ReadExcel
from WebAutoTest.page.org_page import OrgPage
class TestOrg(unittest.TestCase):
@classmethod
def setUpClass(cls):
# 获取DemPage类对象
cls.org = OrgPage()
cls.db = DB()
@classmethod
def tearDownClass(cls):
cls.org.close()
@parameterized.expand(ReadExcel("组织管理", "添加组织").get_data())
def test_add_org(self, case_data, expect_data, sql_data):
if sql_data:
self.db.delete(sql_data)
res = self.org.add_org(name=case_data[0], code=case_data[1])
# 加截图
self.org.get_png(f"{expect_data}.png")
self.assertEqual(expect_data, res)运行层
整理思路:运行层将每个用例层的用例进行调用,通过测试套进行测试,并导入unittestreport来输出报告。
import unittest
import unittestreport
from WebAutoTest.common.read_ini import ReadIni
suite = unittest.TestSuite()
loader = unittest.TestLoader()
ini = ReadIni()
suite.addTests(loader.discover(ini.get_case_dir("case_dir"), pattern="test*.py"))
runner = unittestreport.TestRunner(
suite=suite,
filename="report.html",
report_dir=ini.get_report_dir("report_dir"),
title='测试报告',
tester='测试员',
desc="XX项目测试生成的报告",
templates=1
)
runner.run()报告层
存放最终测试结果,记录日志报告,输出测试报告。
__init__.py
整理思路:在整个自动化文件中的__init__文件中编写日志文件,方便收集并了解错误的问题。
import functools
import logging
import os
# from cgitb import handler #这里的导入为python2.x的版本会有这个来使用handler,新版不需要
from datetime import datetime
class GetLog:
__instance = None
def __new__(cls, *args, **kwargs):
if cls.__instance is None:
"""获取日志的Logger"""
cls.logger = logging.getLogger()
cls.logger.level = logging.INFO
# 日志文件目录
log_dir = os.path.join(os.path.join(os.path.dirname(__file__), "report"), "log")
# 日志文件的名称
log_name = "WebAutoTest_" + datetime.strftime(datetime.now(), "%Y_%m_%d_%H_%M_%S") + ".log"
log_path = os.path.join(log_dir, log_name)
handler = logging.FileHandler(log_path, mode="a", encoding="utf-8")
formatter = logging.Formatter('%(levelname)s - %(asctime)s -: %(message)s')
handler.setFormatter(formatter)
cls.logger.addHandler(handler)
cls.__instance = super().__new__(cls, *args, **kwargs)
return cls.__instance
def info(self, msg):
self.logger.info(msg)
def error(self, msg):
self.logger.error(msg)
def log(param):
@functools.wraps(param)
def inner(*args, **kwargs):
get_log = GetLog()
get_log.info(f'执行的功能为:{param.__name__}, 传入的参数为:{args if args else kwargs}, 所在的文件为:{param.__code__.co_filename}, 所在的行为:{param.__code__.co_firstlineno}')
try:
result = param(*args, **kwargs)
except Exception as e:
get_log.error(
f'执行的功能为:{param.__name__}, 传入的参数为:{args if args else kwargs}, 产生错误,错误为:{type(e)}, 错误的描述信息为:{e}, 所在的文件为:{param.__code__.co_filename}, 所在的行为:{param.__code__.co_firstlineno}')
raise e
else:
return result
return inner
Comments NOTHING