
性能测试是软件测试的一种类型,主要用于评估系统在不同负载条件下的稳定性、响应速度、资源占用和扩展能力,确保系统在高并发、大数据量或长时间运行的情况下仍能保持良好性能。
性能测试的主要目标
- 评估系统瓶颈:发现CPU、内存、磁盘I/O、网络等资源的使用情况。
- 验证系统容量:确定系统能支持的最大用户并发数或数据吞吐量。
- 优化系统性能:通过测试数据分析,优化代码、数据库、服务器配置等。
- 确保稳定性:检查系统在长时间运行(如7×24小时)后是否会出现内存泄漏或性能下降。
性能测试的主要类型
| 测试类型 | 目的 | 典型场景 |
|---|---|---|
| 基准测试(Baseline Testing) | 测量系统在正常负载下的性能指标(如响应时间、TPS) | 新系统上线前建立性能基准 |
| 负载测试(Load Testing) | 模拟不同用户并发量,观察系统表现 | 评估系统在预期用户量下的表现 |
| 压力测试(Stress Testing) | 逐步增加负载,直到系统崩溃,找出极限值 | 确定系统的最大承载能力 |
| 并发测试(Concurrency Testing) | 模拟多用户同时操作,检查数据一致性 | 电商秒杀、票务系统抢购 |
| 稳定性测试(Endurance Testing) | 长时间运行系统,检查内存泄漏或性能下降 | 服务器7×24小时运行是否稳定 |
| 容量测试(Capacity Testing) | 评估数据库、缓存等存储组件的处理能力 | 大数据量写入时,数据库是否出现性能问题 |
| 配置测试(Configuration Testing) | 为了合理地调配资源,提高系统运行效率,通过测试手段来获取、验证、调整配置信息的过程 | 1.配置是广义的一个概念,包括硬件、操作系统、数据库、JVM等所有影响系统性能的配置项 2.配置测试一般用于系统性能调优和能力规划。 |
性能测试的关键指标
- 响应时间(Response Time):用户请求到系统返回的时间(如API平均响应时间 ≤ 500ms)。
- 吞吐量:吞吐量是指系统在单位时间内处理客户端请求的数量,不同的角度,吞吐量的计算方式可以不一样
- 从业务角度:吞吐量可以用事务数/秒(TPS)、请求数/秒(RPS)、页面数/秒、人数/天等来进行衡量计算;
- 从网络角度:吞吐量可以用字节数/秒来进行衡量计算;
- TPS(Transactions Per Second):每秒处理的事务数(如支付系统要求 TPS ≥ 1000)。
- QPS(Queries Per Second):每秒查询数(如搜索引擎要求 QPS ≥ 10,000)。
- 并发用户数(Concurrent Users):同时在线操作的用户数量。
- 错误率(Error Rate):失败请求占比(通常要求 ≤ 0.1%)。
- 资源占用(CPU/Memory/Disk I/O):服务器资源使用情况(如CPU ≤ 80%)。
- 其他指标
- PV(Page View):页面浏览量,用户每一次对网站中的每个页面访问均被记录1次。用户对同一页面的多次刷新,访问量累计;
- UV(Unique visitor):独立访客,通过客户端的cookies实现。即同一页面,客户端多次点击只计算一次,访问量不累计;
- IP:即Internet Protocol,本意本是指网络协议,在数据统计这块指通过ip的访问量。即同一页面,客户端使用同一个IP访问多次只计算一次,访问量不累计。
性能测试的工具
(1)Web/API 性能测试
- JMeter(Apache开源,支持HTTP/HTTPS、数据库、MQ等协议)
- Locust(Python编写,支持分布式压测)
- Gatling(Scala编写,适用于高并发测试)
(2)数据库性能测试
- SysBench(MySQL/PostgreSQL基准测试)
- TPC-C(OLTP事务处理测试标准)
(3)全链路压测
- 阿里云PTS(商业工具,支持大规模分布式压测)
- LoadRunner(商业工具,企业级性能测试)
Jmeter性能测试
在Jmeter中使用线程组能够发起并发,但是他们不能做到真正意义上的并发,中间会有几秒或几十秒的延迟。这个时候就需要用到同步定时器来进行并发的调整。通过同步定时器设置的时间能够保证在几秒后同时发送报文。但是普通线程组+同步定时器只能做并发测试不能做持续并发并且有几秒的时间间隔,这个时候就需要选择Jmeter中的并发线程组来进行阶梯和持续性的并发。
步骤:
- 在https://jmeter-plugins.org/install/Install/网站中下载jmeter的插件管理器。放到相应的目录后重启
- 在jmeter的左上角会有蝴蝶形状的按钮,就是插件管理器,点击进入。
- 下载3 basic graphs、custom thread groups这两个插件。
安装完成后会有5个并发线程组和3个性能监听器。
bzm-Concurrency Thread Groups:并发线程组,以阶梯的形式启动并发
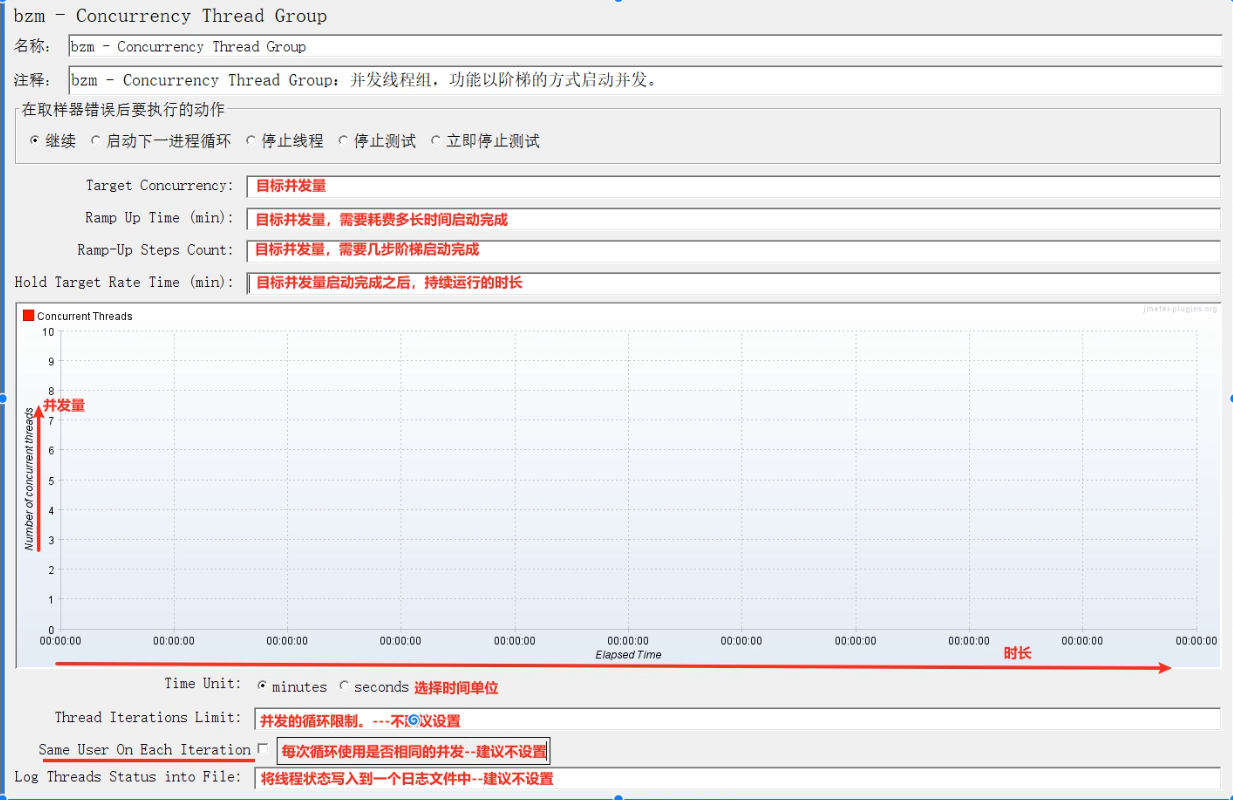
jp@gc-Stepping Thread Group:阶梯线程组,功能为并发线程组的高级使用方式,不光能够阶梯启动并发,也能够阶梯关闭并发。
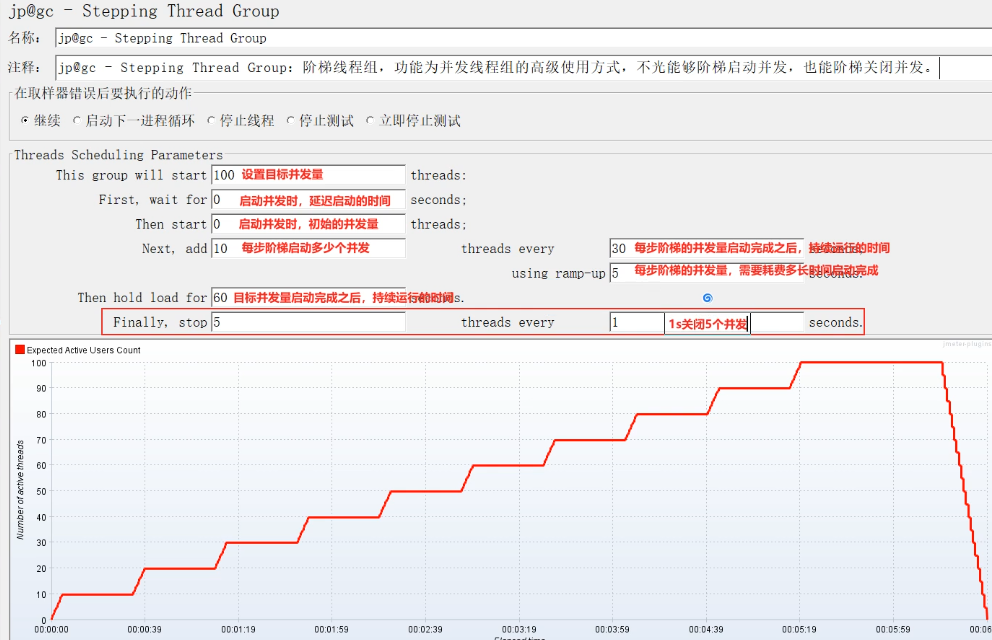
bzm-Arrivale Thread Group:到达线程组,功能测试系统的RPS、TPS、QPS等业务指标。
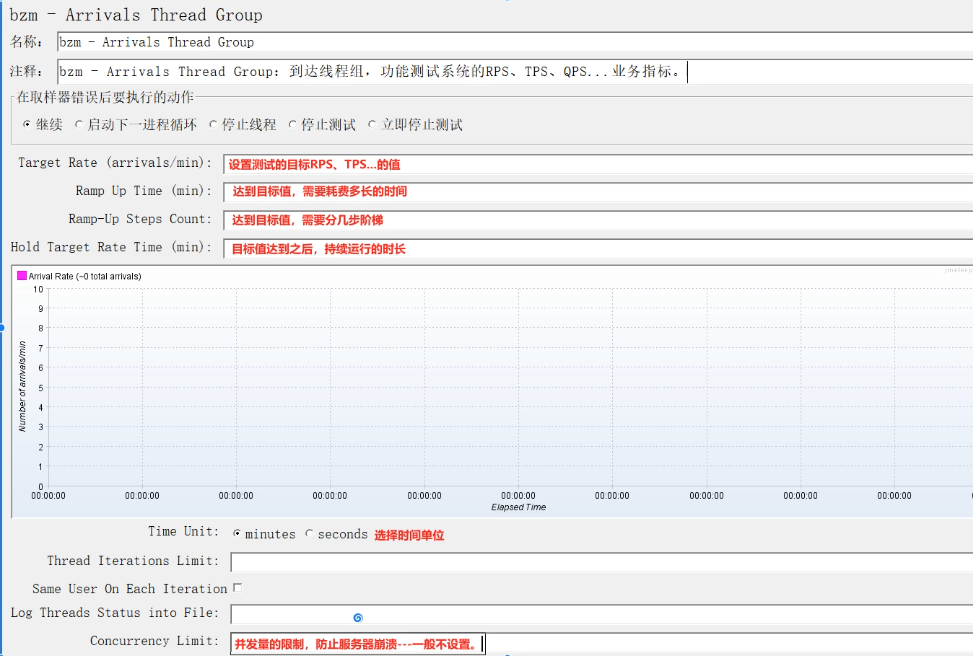
bzm-Free-Form Arrivals Thread Group:自由风格的达到线程组,功能为可以设置每个时间段内的RPS、TPS等
jp@gc-Ultimate Thread Group:旗舰线程组,功能为测试每个时间段内的并发。
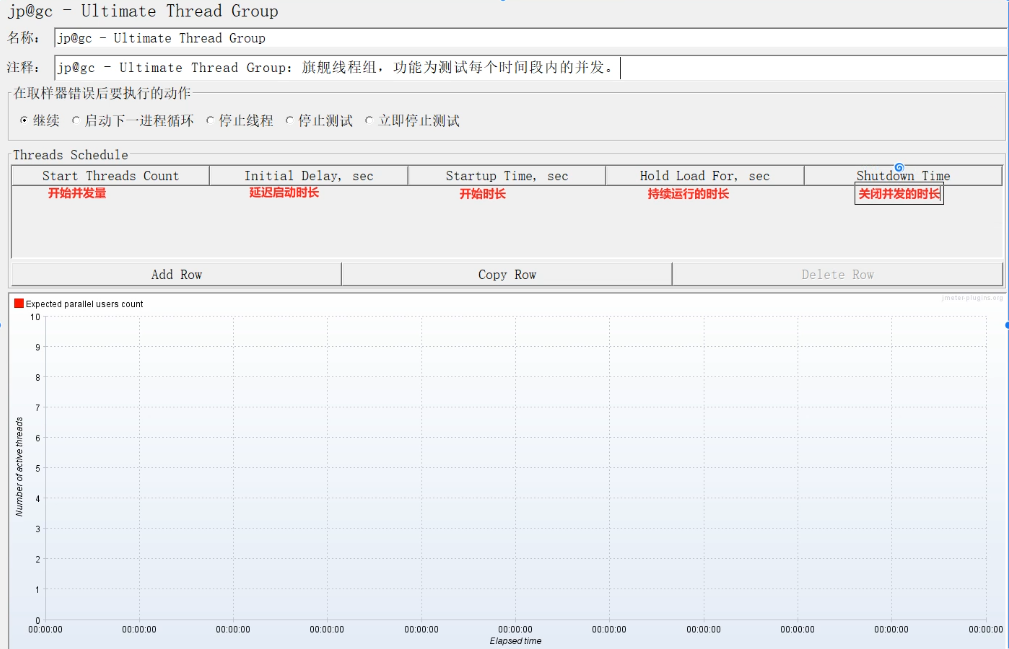
Jmeter分布式
在做性能测试的时候有时会需要大量的并发量对核心的业务进行测试,这个时候单台的Jmeter测试机会有一定的瓶颈。Jmeter起一个线程大概需要2M,那么16GB内存最多大概只能启动8192个线程,这个时候一台Jmeter测试机就不满足测试的需求,Jmeter的分布式就是为了解决这个问题。
分布式通过一台调度机(master)和执行机(slave)来完成分布式的操作,通过配置文件进行关联,再启动Jmeter-server启动slave模式,脚本再调度机上编辑然后通过执行机执行。
执行机配置:
server_port=1099
server.rmi.localport=1099
server.rmi.ssl.keystore.file=rmi_keystore.jks
server.rmi.ssl.truststore.file=rmi_keystore.jks
server.rmi.ssl.disable=true
调度机配置:
remote_hosts=192.168.28.107:1099,192.168.28.108:1099,192.168.28.109:1099
server.rmi.ssl.keystore.file=rmi_keystore.jks
server.rmi.ssl.truststore.file=rmi_keystore.jks
server.rmi.ssl.disable=true
注意:在执行机上的第三方库需要与调度机一致
性能测试监控
Prometheus
Prometheus:Prometheus(由go语言(golang)开发)是一套开源的监控&报警&时间序列数 据库的组合。适合监控docker容器。因为kubernetes(俗称k8s)的流行带动 了prometheus的发展。Prometheus会时刻采集服务器的资源指标数据,存放到时间序列数据库中。
时间序列数据
按照时间顺序记录系统、设备状态变化 的数据被称为时序数据。 应用的场景很多, 如: 无人驾驶车辆运行中要记录的经度,纬度,速度,方向,旁边物体的距 离等等。每时每刻都要将数据记录下来做分析。 某一个地区的各车辆的行驶轨迹数据 传统证券行业实时交易数据 实时运维监控数据等
特点:性能好 关系型数据库对于大规模数据的处理性能糟糕。NOSQL可以比较好的处理 大规模数据,让依然比不上时间序列数据库。 存储成本低 高效的压缩算法,节省存储空间,有效降低IO Prometheus有着非常高效的时间序列数据存储方法,每个采样数据仅仅占 用3.5byte左右空间,上百万条时间序列,30秒间隔,保留60天,大概花了 200多G(来自官方数据)
Prometheus的主要特征
多维度数据模型 灵活的查询语言 不依赖分布式存储,单个服务器节点是自主的 以HTTP方式,通过pull模型拉去时间序列数据 也可以通过中间网关支持push模型 通过服务发现或者静态配置,来发现目标服务对象 支持多种多样的图表和界面展示
Prometheus原理架构图
工作流程如下:
- 配置目标(Targets):你在Prometheus的配置文件(
prometheus.yml)中定义要监控的目标(例如,一个Java应用的API地址10.0.0.1:8080)。 - 暴露指标(Metrics):被监控的应用需要集成一个客户端库(如Prometheus官方提供的Java、Go、Python等库)或在旁边运行一个导出器(Exporter)。这些库和导出器会创建一个HTTP端点(通常是
/metrics),以纯文本格式暴露当前的监控指标数据。 - 定时抓取(Scrape):Prometheus服务器会根据配置的抓取间隔(例如,每15秒一次),主动地、定期地向这些配置好的目标的
/metrics端点发起HTTP GET请求。 - 存储数据:Prometheus接收到HTTP响应后,会解析并存储这些时间序列数据到其内置的时序数据库中。
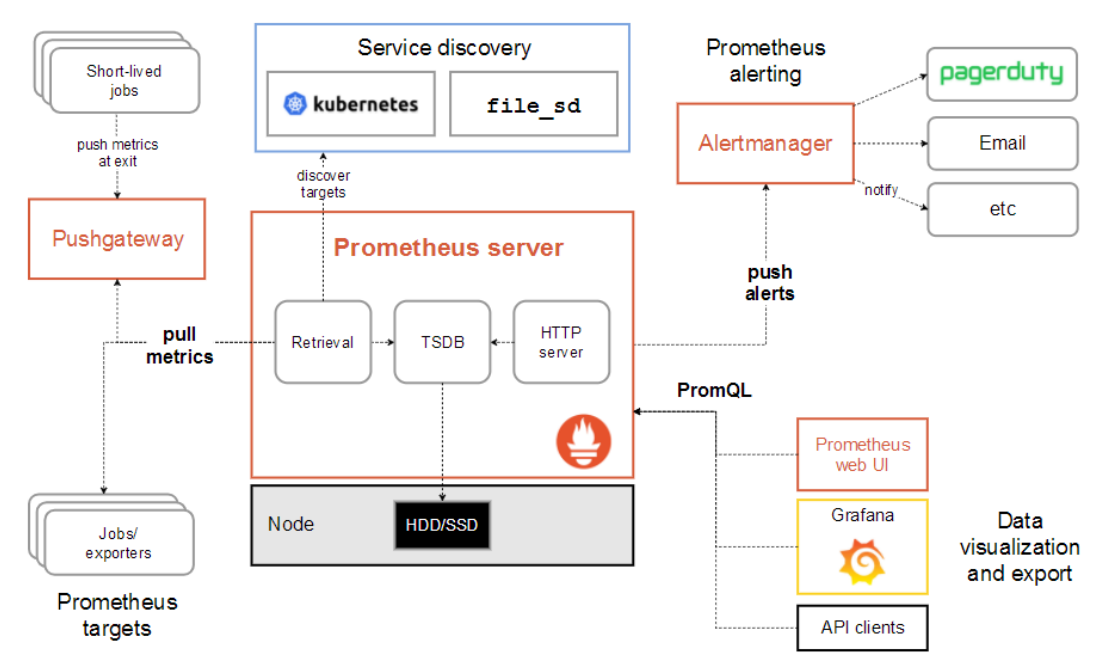
总结:基于HTTP协议的、主动拉取(Pull)模型。它通过主动从目标抓取数据,完美适应了现代云原生环境动态、易变的特性,并辅以多维度数据模型和强大的PromQL查询语言,共同构成了其强大监控能力的基石。
性能测试实战
环境信息:
- 操作系统:CentOS7.9,1核4G内存20GB硬盘(vmware)
- 数据库:MySQL5.6
- 应用服务器:Tomcat8
- 项目:jforum
- 性能测试工具:Jmeter
- 监控工具:Prometheus+Grafana+InfluxDB
第一步搭建项目
描述:这个项目是一个jforum论坛项目,主要的功能为发帖,只需要在前端使用war包就可以进行部署了。
cd /usr/local/ #切换目录
tar -zxvf jdk #安装java环境
tar -zxvf apache-tomcat-8.5.29.tar.gz #安装tomcat服务器
vi /etc/profile #编辑环境变量
export JAVA_HOME=xxxx #设置环境变量
source /etc/profile #重置环境变量
#将jforum项目放入tomcat的webapp中
#在/tomcat/conf/server.xml中可修改端口号
#修改完后在tomcat/bin目录中./startup.sh启动项目
#安装mysql第二步安装普罗米修斯(Prometheus)
关闭防火墙或允许应用端口防火墙通过
systemctl stop firewalld
systemctl disable firewalld安装普罗米修斯
tar xf prometheus-2.5.0.linux.amd64.tar.gz -C /usr/local/
mv /usr/local/prometheus-2.5.0.linux.amd64/ /usr/local/prometheus
直接使用默认配置文件启动
./prometheus --config.file=./prometheus.yml &
确认端口(9090)
lsof -i:9090第三步安装并配置node_export
首先进入网页
在status中的target health中可以查看所采集的目标主机

在服务器中安装并启动node_export
tar -zxvf node_exporter-1.9.1.linux-amd64.tar.gz #解压node_exporter
./node_exporter --web.listen-address=:9111 #修改端口启动修改prometheus的配置文件
cd prometheus
vi prometheus.yml
#最后一行添加
- job_name: "prometheus" #任务名称
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"] #配置数据来源
# The label name is added as a label `label_name=<label_value>` to any timeseries scraped from this config.
labels:
app: "prometheus" #应用名称配置完成后重启prometheus
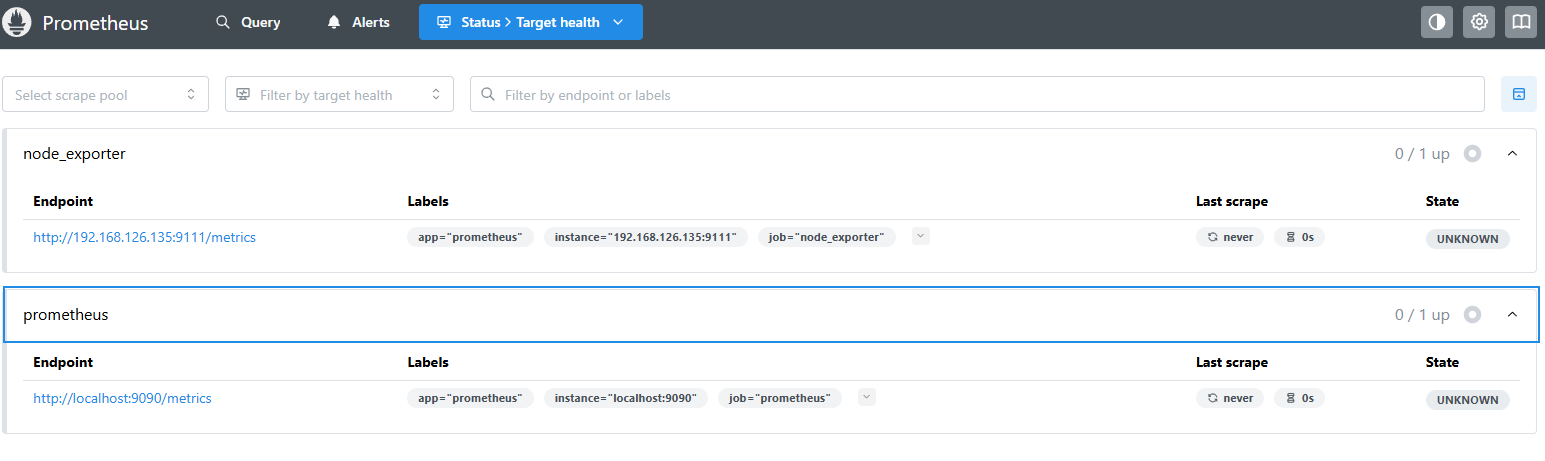
这个时候点击url就可以查看采集的数据了
第四步安装grafana可视化工具并添加数据源
yum install -y https://dl.grafana.com/grafana-enterprise/release/12.1.1/grafana-enterprise_12.1.1_16903967602_linux_amd64.rpm #安装grafana
systemctl start grafana-server #启动grafana,默认端口3000,初始用户名:admin,密码:admin第一次进入网页需要修改密码
在Connections-Data sources中添加数据源
在数据源中修改url和请求方式并保存
创建监控面板,通过导入官方面板来创建。通过官方模板的ID来导入面板。https://grafana.com/grafana/dashboards/
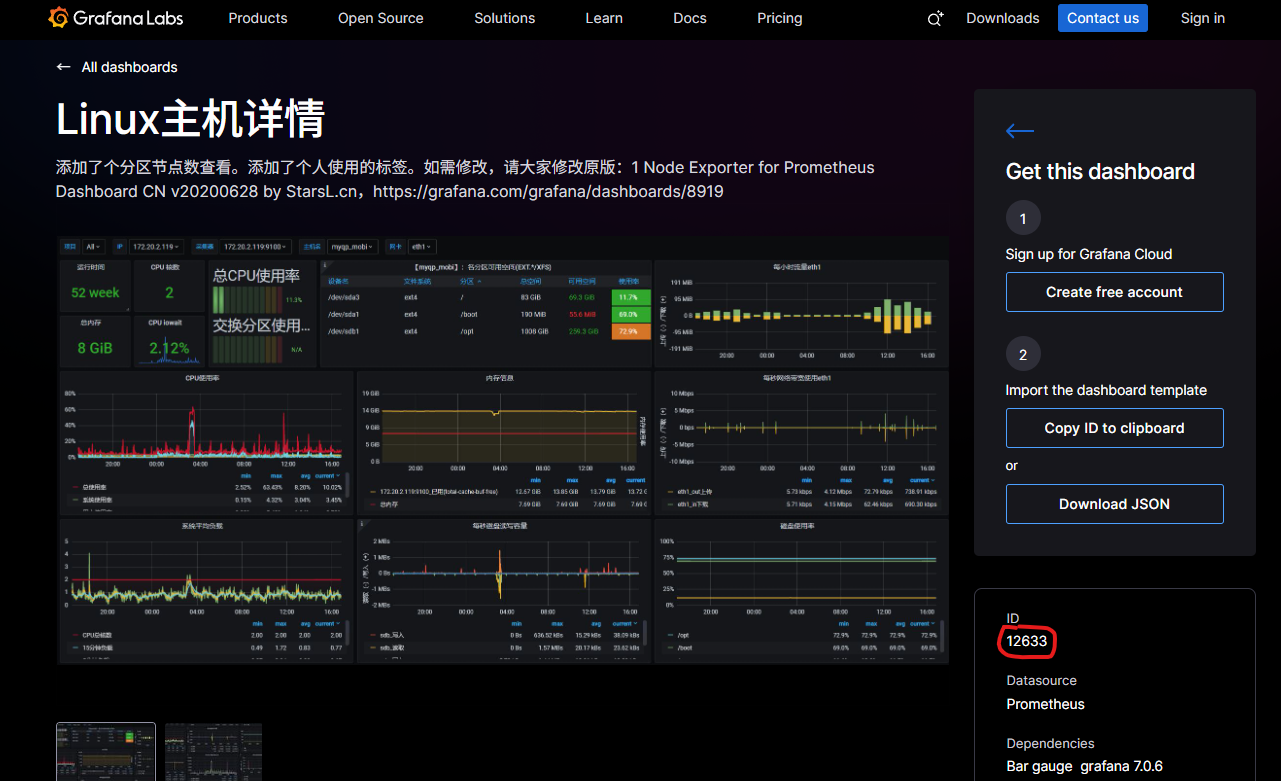
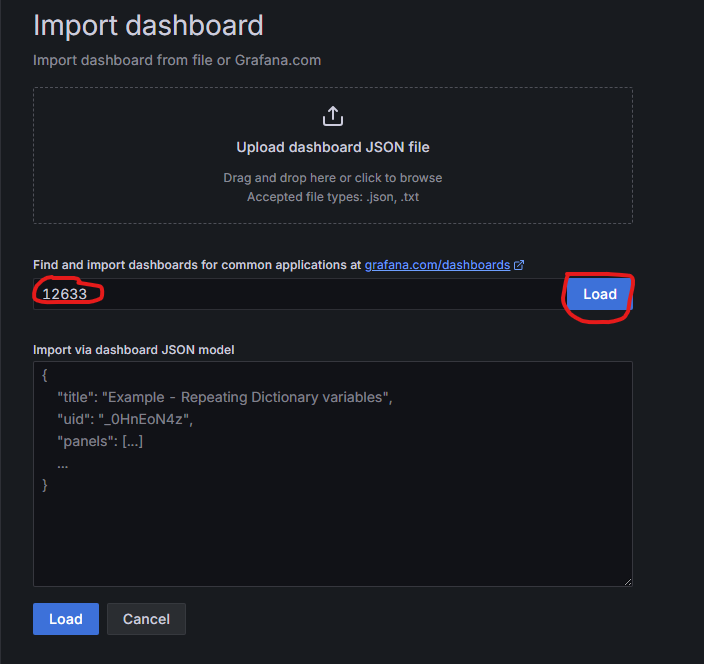
在面板中添加数据源,即可创建面板
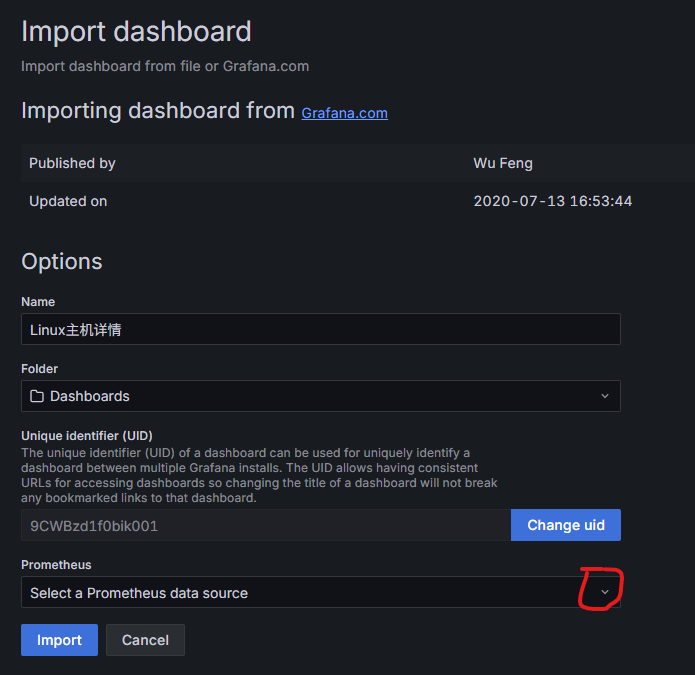
这样就创建了一个监控内容
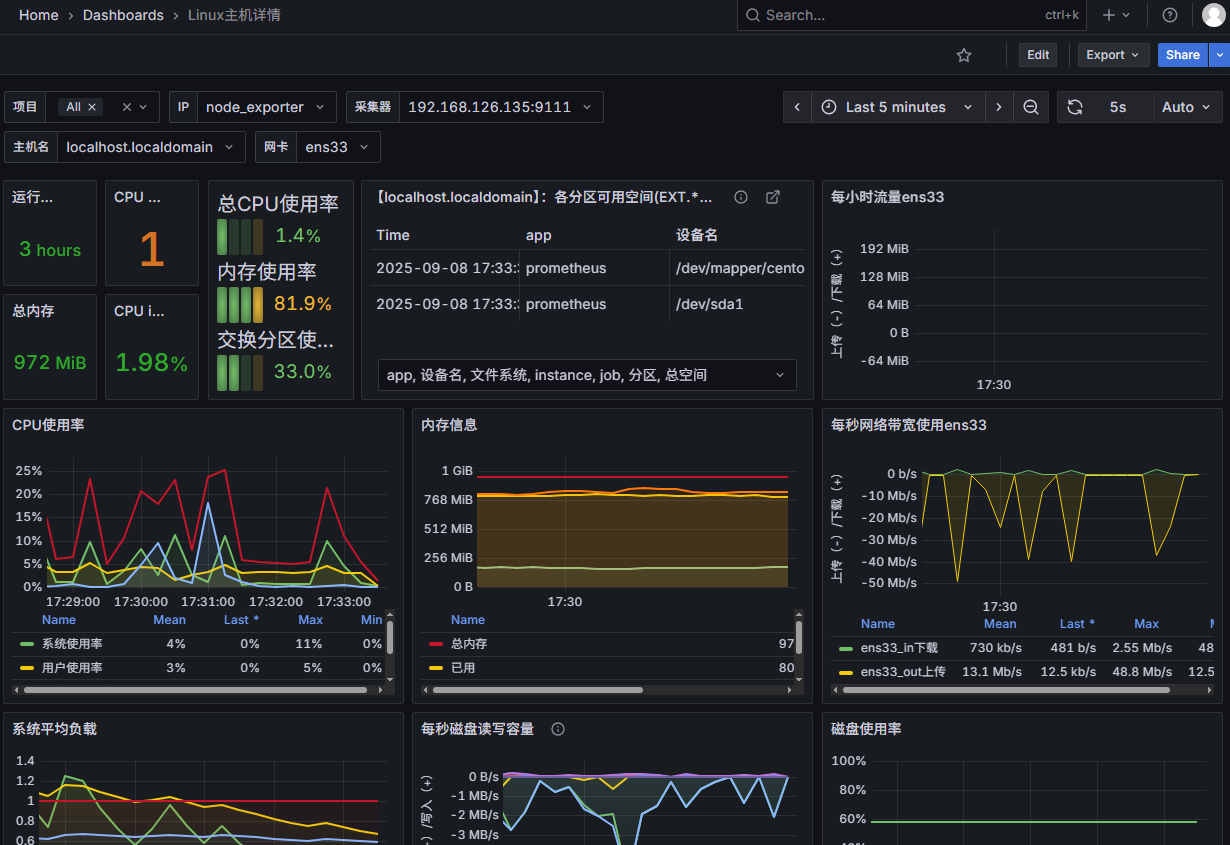
最后发起并发测试就可以查看效果了。
第四步安装InfluxDB
解决了资源指标的监控,还需要解决业务指标的监控,这里就会用到另一个数据源InfluxDB。在Jmeter中可以通过后端监听器选择InfluxDB将数据采集到后存放到InfluxDB,最后在grafana进行展示。InfluxDB是通过golang开发的时间序列数据库。
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.8.0.x86_64.rpm
yum install -y localinstall influxdb-1.8.0.x86_64.rpm
systemctl start influxdb
systemctl enable influxdb
ss -tan | grep 8086连接数据库
influx -host 'localhost' -port '8086'
CREATE DATABASE "jmeter"; #创建数据库
show databases; #查看所有数据库
#创建数据库数据保留时长策略:3w=3周 3d=day 3h=3小时
USE jmeter; # 切换数据库
create retention policy "rp_3d" on "jmeter" duration 3d replication 1 default;
show retention policies on "jmeter"; #查看策略是否修改成功添加influxDB数据源
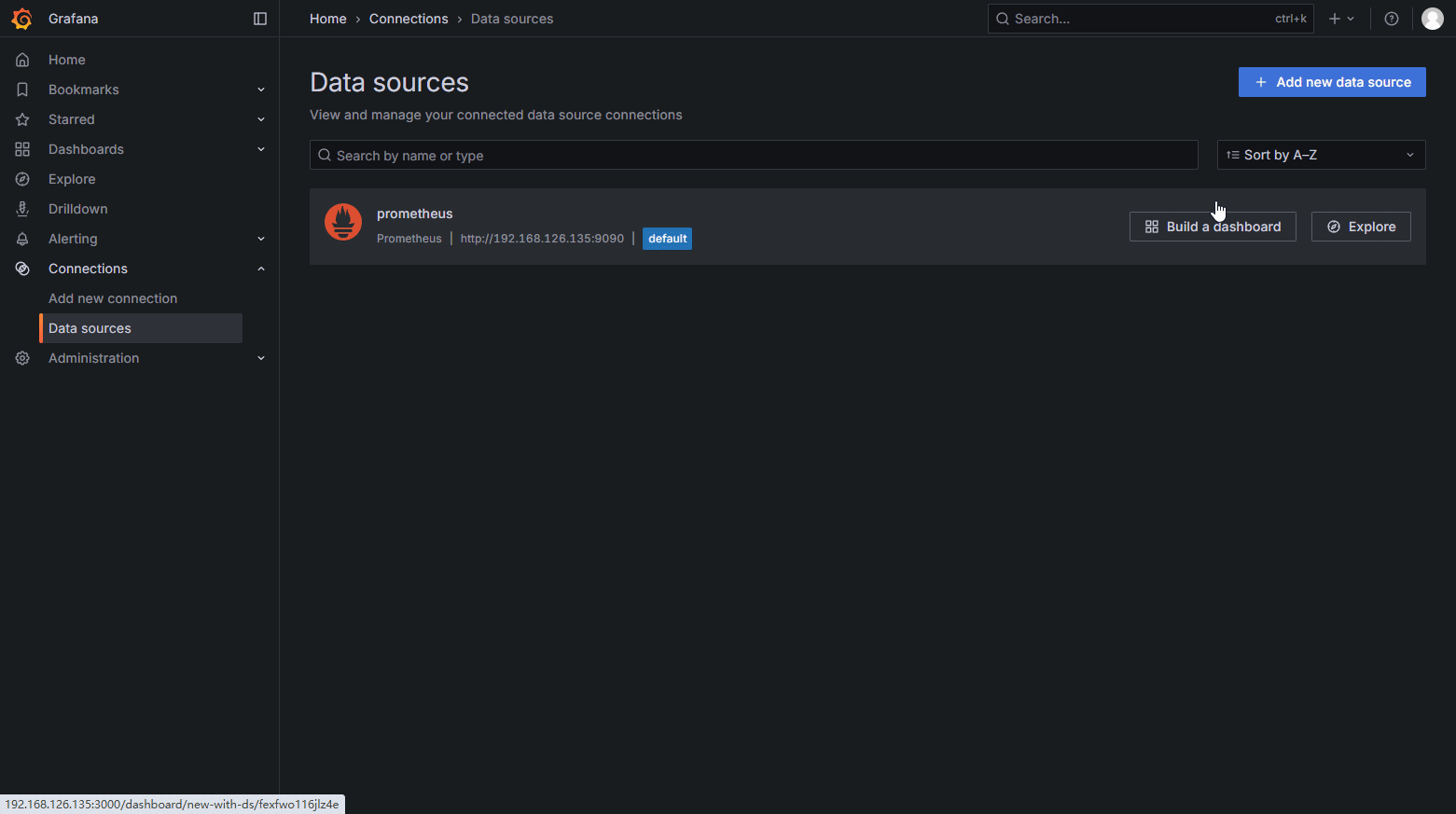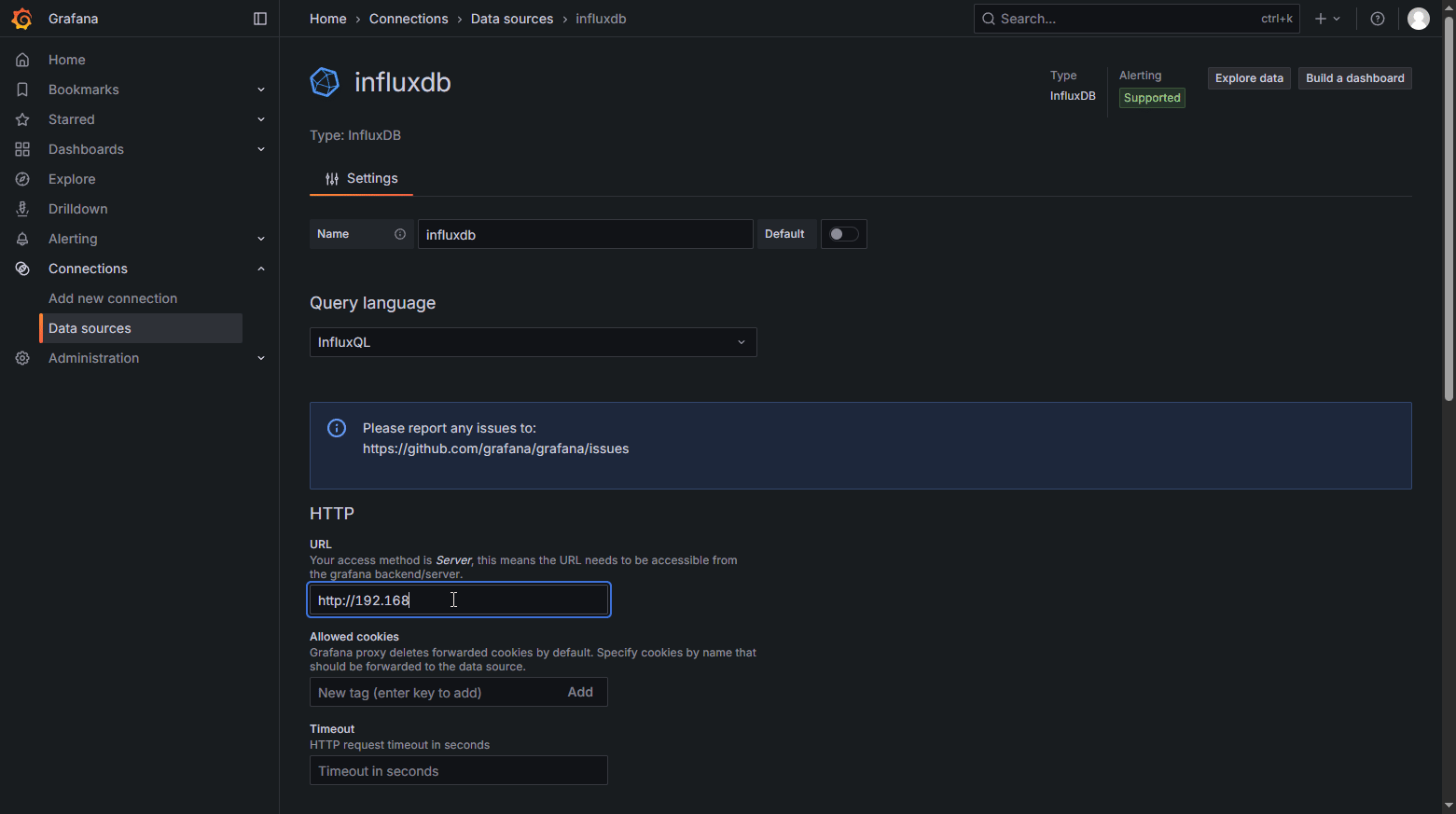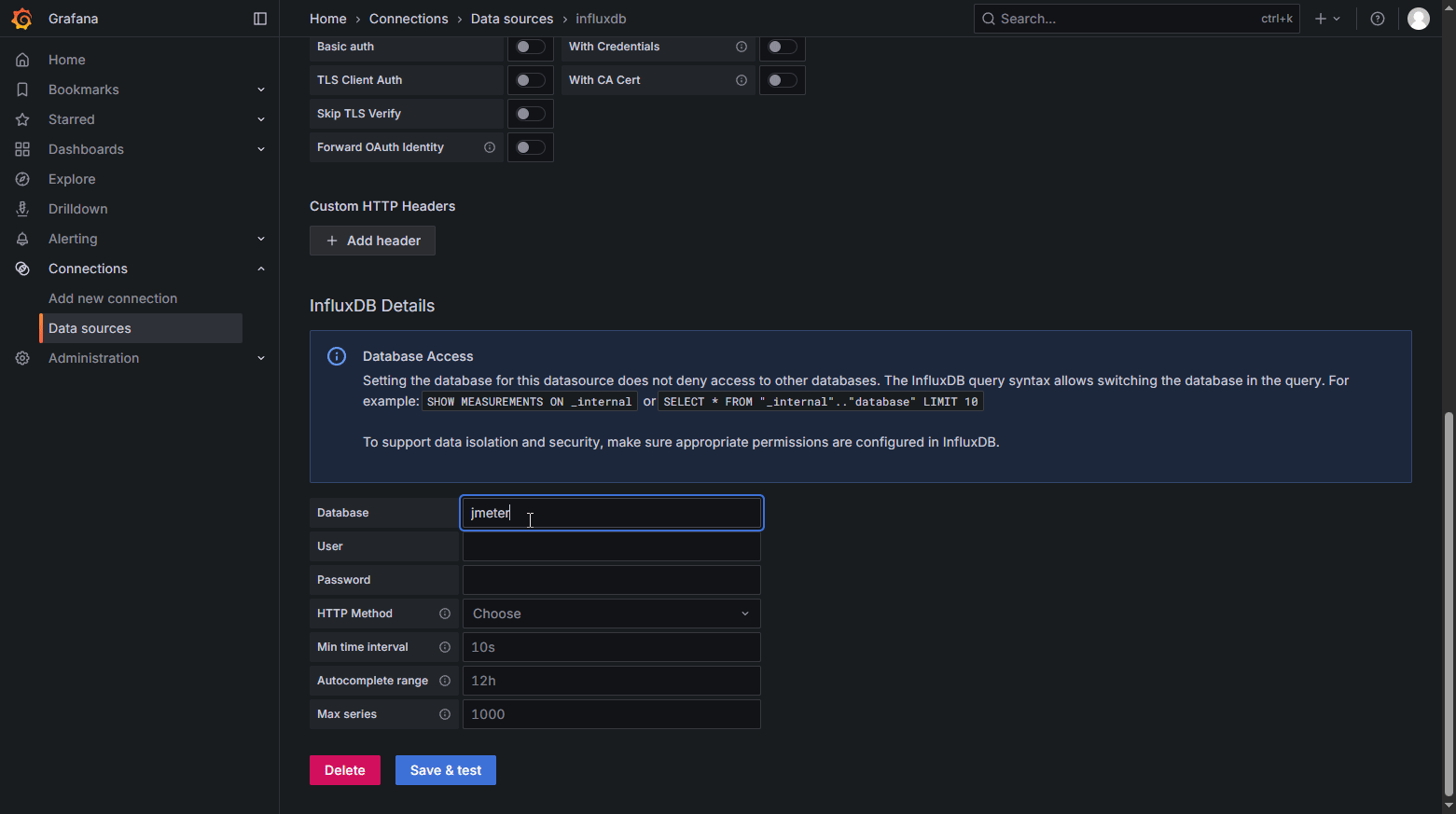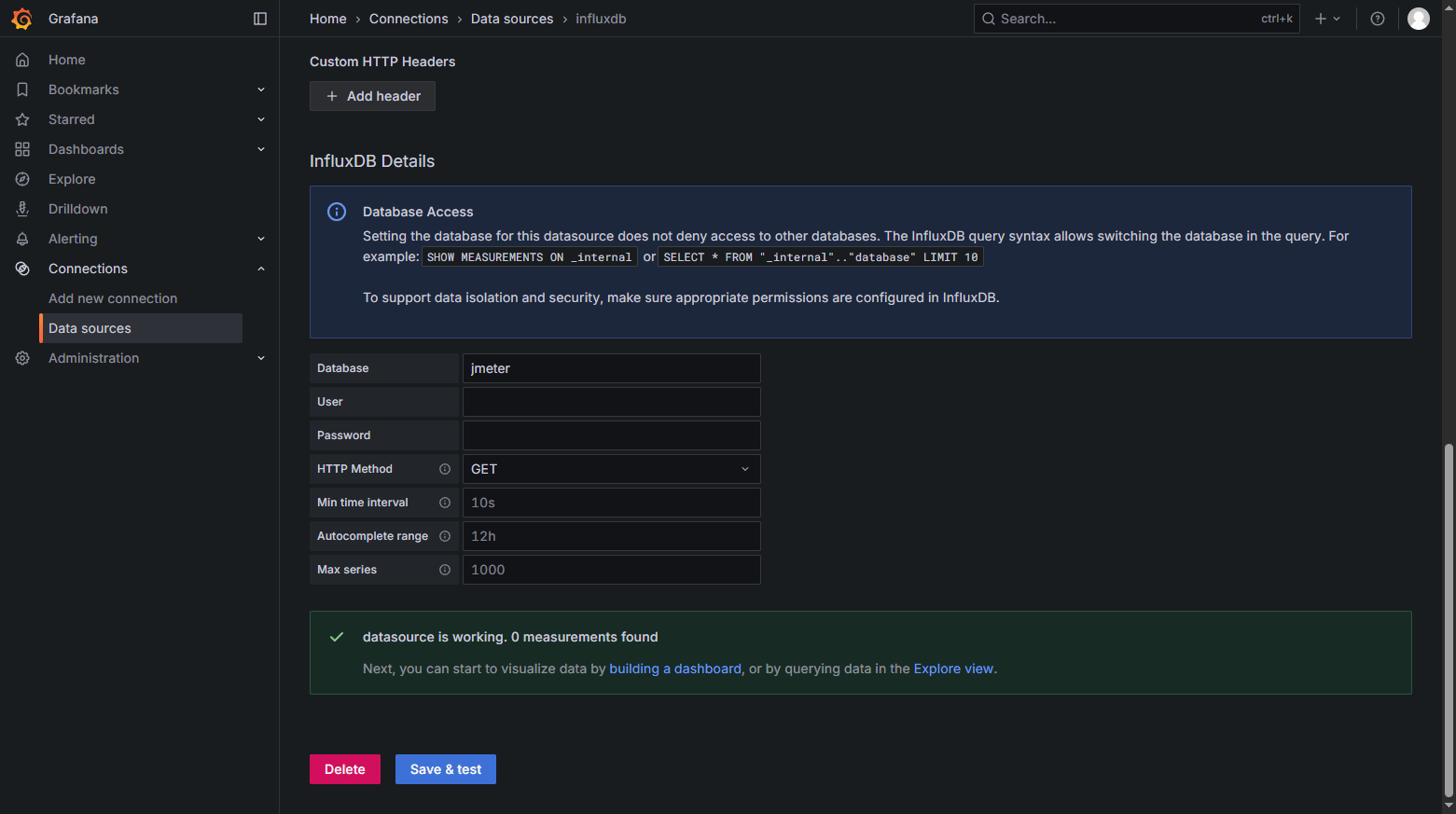
添加面板
过程与之前一致,不过这里要小心需要选择带有jmeter后端监听器样式的模板
配置jmeter后端监听器
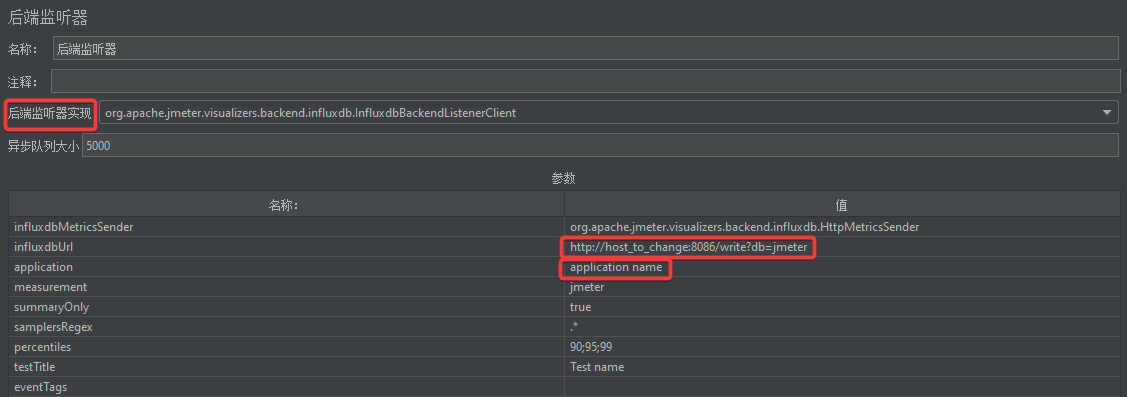
这边写好之后就可以在面板上选择应用来进行监控
监控业务指标
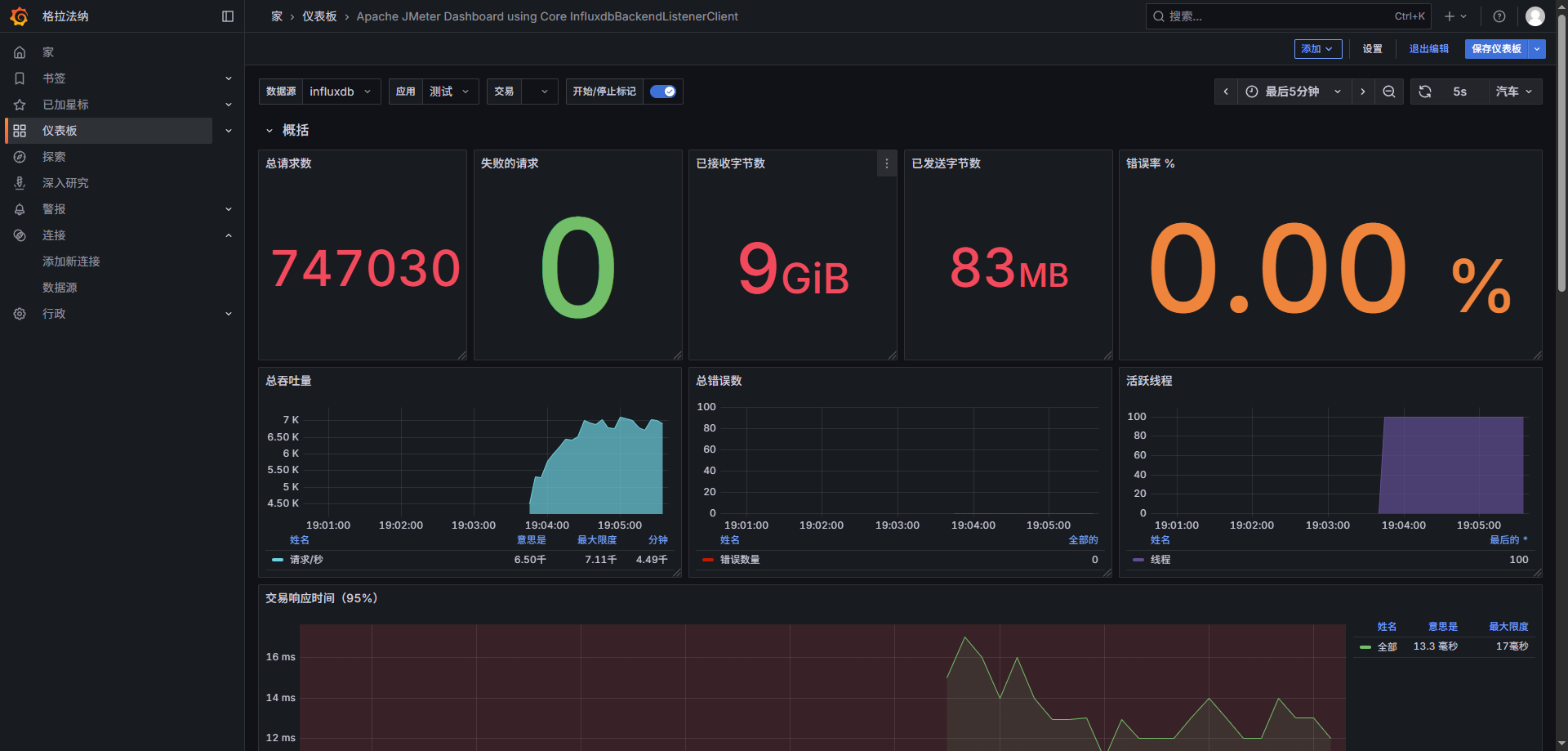
Comments NOTHING